위의 자료를 번역한 내용입니다.
--------------------------------------
Coordinate Systems
지난 튜토리얼에서 우리는 변환 행렬로 모든 정점들을 변환하여 행렬을 어떻게 이용하는지를 배웠었다. OpenGL은 모든 정점들이, 우리에게 보이길 원하는, 각 vertex shader가 작동한 후에 정규 장치 좌표에 있기를 기대한다. 즉, 각 정점의 x,y, z 좌표가 -1.0과 1.0사이에 있어야만 한다. 이 범위 밖의 좌표들은 보이지 않을 것이다. 우리가 보통 하는 것은 우리가 우리자신을 설정한 범위에서 좌표를 명시하고, vertex shader에서 이러한 좌표를 NDC로 변환한다. 이러한 NDC 좌표들은 그런 후에 그것들을 너의 스크린에 있는 좌표/픽셀들로 변환하기 위해 rasterizer에게 주어진다.
좌표들을 NDC로 변환하고 스크린 좌표로 바꾸는 것은 보통 우리가 마지막으로 그것들을 스크린 좌표로 바꾸기전에 한 객체의 정점들을 몇 가지 좌표체계로 바꾸는 몇 가지 fashion으로 성취된다. 그것들을 중간 좌표계로 바꾸는 이점은 몇 몇 연산/계산들이 곧 명백히질 어떤 좌표계에서는 더 쉽다는 것이다. 우리에게 중요한 총 5개의 다른 좌표계가 있다.
- Local space (or Object space)
- World space
- View space (or Eye space)
- Clip space (Screen space)
그러한 것들은 모두 우리의 정점들이 fragment로 끝나기전에 변환될 다른 상태이다.
너는 아마도 지금 실제로 공간 또는 좌표계가 무엇인지에 의해 혼란 스러울 것이다. 그래서 우리는 그것들을 전체 그림과 각 세부 공간이 실제로 무엇을 하는지 보여주어서 좀 더 이해가능한 방식으로 그것들을 설명할 것이다.
The global picture
한 공간에서의 좌표를 다음 좌표 공간으로 바꾸기 위해서, 우리는 model, view, projection 행렬이 가장 중요한 몇 가지 변환 행렬들을 사용할 것이다. 우리의 vertex 좌표들은 처음에 local space에서 local 좌표로서 시작한다. 그리고나서 나중에 world 좌표, view 좌표, clip 좌표로 처리되고, 그리고 결국에 screen 좌표로 끝날 것이다. 다음 이미지는 그 프로세스를 보여주고 변환이 무엇을 하는지를 보여준다.
1. Local 좌표들을 그것의 local origin과 관련된 너의 객체의 좌표들이다; 그것들은 너의 객체가 시작하는 좌표이다.
2. 그 다음 단계는 local 좌표들을 world-space 좌표들로 변환하는 것이다. world-space 좌표는 더 큰 world와 관련된 좌표들이다. 이러한 좌표들은 world의 global origin과 관련된다. 그리고 많은 다른 객체들은 또한 그 world의 origin과 상대적으로 배치되어 진다.
3. 다음은 우리는 그 world 좌표들을 view-space 좌표들로 변환한다. 이것은 각 좌표가 카메라 또는 보는 사람의 관점으로부터 보여지도록 하는 방식으로 된다.
4. 좌표가 view space에 있게 된 후에, 우리는 그것들을 clip 좌표들로 project시키고 싶어한다. clip coordinate는 -1.0 ~ 1.0의 범위로 처리되고, 어떤 정점들이 스크린에 남아 있을지를 결젖ㅇ한다.
5. 그리고 마지막으로 우리는 clip 좌표들을 screen 좌표로 변환하는데, 우리가 viewport transform이라 부르는 과정에서 처리된다. 그 viewport transform은 -1.0 ~ 1.0의 좌표를 glViewport로 정의되는 좌표 범위로 변환한다. 그 결과 좌표들은 그러고나서 fragments로 바뀌기 위해 rasterizer에 보내진다.
너는 아마 각 개별 공간이 무엇을 위해 사용되는지 조금 이해 했을 것이다. 우리가 우리의 정점들을 모든 이러한 다른 공간으로 변환하는 이유는 몇 몇 연산들은 좀 더 말이 되고 또한 어떤 좌표계에서 사용하기 더 쉽기 떄문이다. 예를들어, 너의 객체를 수정할 때, local space에서 이것을 하는 것이 더욱 이해가 된다. 반면에 다른 객체들의 위치와 관련하여 그 객체에 대해 어떤 연산을 계산하는 것은 world 좌표에서 좀 더 이해가 잘된다. 등등. 만약 우리가 원한다면 우리는 한 번에 local space에서 clip space로 가는 변환 행렬을 정의할 수도 있다. 그러나 그것은 우리에게 융통성을 가져간다.
우리는 각 좌표계에 대해 더 세부적으로 아래에서 이야기 할 것이다.
Local space
Local space는 너의 너의 오브젝트에 local인 좌표 공간이다. 즉, 너의 오브젝트가 시작하는 곳이다. 너가 Blender같은 모델링 소프트웨어 패키지에서 너의 정육면체를 만들었다고 상상해보자. 너의 정육면체의 origin은 아마 (0, 0, 0)에 있다. 비록 너의 정육면체가 너의 최종 프로그램에서 다른 위치에 있을지라도. 아마도 너가 만든 모든 모델들은 모두 그들의 원래 위치로서 (0,0,0)을 가진다. 너의 모델들의 정점들을 그러므로 local space에 있다. 그것들은 모두 너의 object에 local한다.
우리가 사용해온 컨테이너의 정점들은 -0.5 ~ 0.5사이의 좌표로서 그것의 원점이 0.0인 좌표로 명시되어있다. 이러한 것들이 로컬 좌표이다.
World space
만약 우리가 프로그램에서 직접적으로 우리의 모든 객체들을 불러온다면, 그것들은 아마 어느정도 우리가 원하는 것이 아닌 (0,0,0)의 world origin 주변에서 서로에게 쌓여 있을 것이다. 우리는 더 큰 world안에 그것들을 위치시키기 위해 각 객체에 대해 위치를 정의하고 싶다. world space에서의 좌표들은 정확히 그것들이 말하는 바이다. 모든 너의 정점들의 좌표가 (game) world와 상대적이다. 이것은 너가 그것들이 (현실적인 방법으로 선호되듯이) 장소 주변에 흩뿌려지는 방식으로 너의 객체들이 변환되는 것을 원하는 좌표 장소이다. 너의 오브젝트의 좌표들은 local에서 world space로 변환된다. 이것은 model matrix로 성취된다.
model matrix는 너의 객체를 그것들이 속하는 위치/방향에 두기 위해 너의 객체를 이동하고, 스케일하고 또는 회전시키는 변환 행렬이다. 그것을 한 집을 스케일 다운하고(그것은 local space에서 너무 크다), 그것을 교외도시로 이동시키고 , 그것이 딱 인접한 집들과 맞도록 y축에 대해 왼쪽으로 조금 회전시키는 것으로 생각해라. 너는 이전 튜토리얼에서 일종의 model matrix로서 어떤 장면에 대해 컨테이너를 위치시키는 matrix를 생각해볼 수 있다.; 우리는 그 컨테이너의 local 좌표를 scene/world에서의 다른 장소로 변환했다.
View Space
view space는 보통 사람들이 OpenGL의 카메라로서 언급하는 것이다. (그것은 가끔 camera space 또는 eye space로서 알려져있다.) view space는 너의 world-space 좌표를 사용자의 view 앞에 있는 좌표로 변환하는 것이다. 그 view space는 따라서 카메라의 관점으로부터 보여지는 공간이다. 이것은 보통 어떤 아이템들이 카메라 앞에 변환되도록 하기 위해 scene을 이동하거나 회전시키는 이동과 회전의 조합으로 이루어진다. 이러한 조합된 변환들은 일반적으로 world 좌표를 view space로 변환하는 view matrix에 저장되어진다. 다음 튜토리얼에서, 우리는 광범위하게 한 카메라를 simulate하기 위해 view matrix 만들지에 대해 이야기할 것이다.
Clip space
각각의 vertex shader 작동의 끝에서, OpenGL은 좌표들이 한 특정한 범위 내에 있는 것을 기대하고, 이 범위 밖의 좌표들은 clipped 된다. 잘려진 좌표들은 버려지고, 그래서 남아있는 좌표들은 너의 스크린에 보이는 fragments로 될 것이다. 이것은 또한 clip space가 그것의 이름을 얻은 이유이다.
모든 보이는 좌표들을 -1.0 ~ 1.0의 범위내에 있도록 명시하는 것은 정말 직관적이지 않기 때문에, 우리는 우리 자신의 좌표 셋이 작동되도록 명시하고, 그것들을 다시 NDC로 변환한다. OpenGL이 그것들을 기대하기 때문에.
view에서 clip-space로 정점 좌표들을 변환하기 위해서, 우리는 소위 각 차원에서 -1000 ~ 1000의 범위 좌표를 명시하는 projection matrix를 정의한다. 그 projection matrix는 그러고나서 이 명시된 범위 내의 좌표들을 normalized device 좌표 (-1.0, 1.0)으로 변환한다. 모든 이 범위 밖의 좌표들은 -1.0 ~ 1.0 사이로 매핑 되지 않을 것이고 그러므로 clipped 된다. 우리가 projection matrix에서 명시한 이 범위로, (1250, 500, 750)인 좌표는 보이지 않을 것이다. 왜냐하면 x 좌표가 범위 밖이고, 따라서 NDC에서 1.0보다 더큰 좌표로 변환되기 때문이다. 그러므로 잘려진다.
Green Box
만약 primitive의 한 부분이 (예를들어 삼각형) clipping volume 밖에 있다면, OpenGL은 clipping range에 맞게 하기 위해 하나 또는 더 많은 삼각형으로서 그 삼각형
을 재구성할 것이다.
projection matrix가 만드는 이 viewing box 소위 frustum이라고 불리고, 이 frustum 내에서 끝나는 각 좌표는 사용자의 스크린에서 끝날 것이다. 명시된 범위에서 2D view-space 좌표로 쉽게 매핑될 수 있는 NDC로 좌표를 변환하는 전체 프로세스는 projection이라고 불린다. projection matrix는 3D 좌표를 매핑하기 쉬운 2D normalized device 좌표들로 사영하기(project) 때문이다.
일단 모든 정점들이 clip space로 변환되면, perspective division이라 부리는 최종 연산이 수행된다. 거기에서 우리는 벡터의 동차 w 요소로 위치 벡터의 x, y, z 요소를 나눈다. perspective division는 4D clip space 좌표들을 3D normalized device 좌표들로 바꾸는 것이다. 이 단계는 각 vertex shader 실행의 끝에서 자동으로 실행된다.
그것은 결과로 만들어진 좌표가 스크린 좌표로 매핑된 단계 후에 일어난다. (glViewport 설정을 사용하여) 그리고 fragments로 변환된다.
view 좌표를 clip 좌표로 변환하는 projection matrix는 두 가지 다른 형태를 취할 수 있다. 거기에서 각 형태는 그것 자신의 독특한 frustum을 정의한다. 우리는 orthographic projection matrix 또는 perspective projection matrix를 만들 수 있다.
Orthographic projection
orthographic 사영 행렬은 박스 밖의 각 정점이 잘려지는 clipping space를 정의하는 cube 같은 frustum box를 정의한다. orthographic projection matrix를 만들 때, 우리는 너비, 높이, 보이는 frustum의 거리를 명시한다. orthographic projection matrix로 clip space로 변환한 후에 이 프러스텀 내에 끝나는 모든 좌표들은 잘려지지 않을 것이다. 그 프러스텀은 컨테이너처럼 보인다.
그 프러스텀은 보이는 좌표들을 정의하고, 너비, 높이 near and far plane에 의해 명시된다. near plane 앞에 있는 어떤 좌표든지 clipped 되고, 같은 것은 far plane 뒤에 있는 좌표들이 적용된다. orthographic frustum은 직접적으로 frustum 내부에 있는 모든 좌표들을 normalized device 좌표들로 매핑한다. 각 벡터의 w요소들이 건드려지지 않기 때문이다. 만약 w 요소가 1.0으로 동일하다면, perspective division은 그 좌표들을 변경하지 않는다.
orthographic projection matrix를 만들기위해서, 우리는 GLM의 내장 함수 glm::ortho를 이용한다.
glm::ortho(0.0f, 800.0f, 0.0f, 600.0f, 0.1f, 100.0f);
처음 두 인자들은 프러스텀의 왼쪽과 오른쪽 좌표를 명시하고, 세 번째 네 번째 인자는 프러스텀의 아래와 윗 부분을 명시한다. 그러한 4 개의 점으로, 우리는 near와 far plane들을 정의한다. 5번째와 6번 째 인자들은 그러고나서 near와 far plane 사이의 거리를 정의한다. 이 특정한 projection matrix는 이러한 x,y,z 범위 값 사이에 있는 모든 좌표들을 normalized device 좌표로 변환한다.
orthographic projection matrix는 직접적으로 너의 스크린에 있는 2D 면으로 좌표를 매핑한다. 그러나 사실, 직접적인 projection은 비현실적인 결과를 만들어낸다. 왜냐하면 그 projection은 perspective(관점)을 고려하지 않기 때문이다. 그것이 perspective projetion 행렬이 우리를 위해 수정하는 것이다.
Perspective proejction
만약 너가 real life가 제공해야만 하는 그래픽스를 즐기려면, 더 멀리 있는 오브젝트들이 더 작게 나타나야 한다는 것을 알 것이다. 이 이상한 효과는 우리가 perspective(원근법)라고 부르는 것이다. 원근법은 특히 다음 이미지에서 보이는 것처럼 무한한 고속도로 또는 철길의 끝을 바라 볼 때 눈에 띈다.
너도 보듯이, 원근법 떄문에, 선들은 그것들이 멀리 있을수록 아주 겹쳐 보인다. 이것은 정확히 perspective projection이 흉내내려 하는 효과이다. 그래서 그것은 perspective projection matrix를 사용하여 그것을 한다. projection matrix 주어진 frustum의 범위를 clip space로 매핑하지만, 한 정점의 좌표가 view로부터 멀어질 수록, 이 w 요소가 더 높아지도록 하는 방식으로, 각 vertex 좌표의 w값을 조작한다. 일단 그 좌표들이 clip space로 변환된다면, 그것들은 -w ~ w의 범위에 있게 된다. (이 범위 밖의 있는 어떤 것이든 잘려진다.) OpenGL은 보이는 좌표들이 최종 vertex shader의 output으로서 -1.0 ~ 1.0 사이에 떨어지도록 요구한다. 따라서 좌표가 clip space에 있기만 한다면, perspective division이 그 clip space 좌표들에 적용된다.
정점 좌표의 각 요소는 한 정점이 viewer로 부터 더 멀어질수록 더 작은 정점좌표를 주면서 그것의 w 요소로 나눠진다. 이것은 w 요소가 중요한 또 다른 이유이다. 그것은 우리가 perspective projection을 하는데 우리를 도와주기 때문이다. 결과 좌표들은 그 후에 normalized device space에 있게 된다. 만약 너가 어떻게 orthographic 과 perspective projection 행렬들이 실제로 계산되는지 아는데 흥미가 있다면 (너무 수학에 두려워 하지마라) 나는 Songho의 이 훌륭한 자료를 추천한다.
perspective projection 행렬은 GLM에서 다음과 같이 만들어질 수 있다.
glm::mat4 proj = glm::perspective(glm::radians(45.0f), (float)width/(float)height, 0.1f, 100.0f);
glm::perspective가 하는 것은 다시 보이는 공간을 정의하는 큰 프러스텀을 만드는 것이다. 그 프러스텀 밖의 어떤 것이든 clip space volume에서 끝날 것이고 따라서 잘려질 것이다. 원근 프러스텀은 단일하지 않은 형태의 박스로서 시각화 되어질 수 있다. 그리고 이 박스안의 각 좌표는 clip space에 있는 한 점으로 매핑 될 것이다. 원근 프러스텀의 한 이미지는 아래처럼 보인다.
그것의 첫 번째 인자는 fov 값을 정의한다. 그것은 field of view를 말하고 그 viewspace가 얼마나 큰지를 정한다. 두 번째 인자는 viewport의 너비를 높이로 나누어 계산된 관점 비율을 설정한다. 세 번째와 네 번째 인자는 프러스텀의 near와 far 면을 설정한다. 우리는 보통 near 거리를 0.1f로 far 거리로 100.0f으로 설정한다. near and far plane 사이의, 프러스텀 안의 모든 정점들을 렌더링 될 것이다.
Green Box
너의 원근 행렬의 near 값을 너무 높에 설정할 때 마다 (10.0f 처럼), OpenGL은 카메라 가까이에 있는 모든 좌표들 (0.0f ~ 10.0f 사이의) 잘라버릴 것이다. 이것은 만약 너가 오브젝트들에 너무 가까이 가면 어떤 객체를 관통해서 보는 비디오게임에서 친숙한 시각적 결과를 줄 것이다.
orthographic projection을 사용할 때, 각 정점 좌표들은 어떤 멋있는 perspective division 없이 직접적으로 clip space로 매핑되어진다. (그것은 여전히 perspective divison을 하지만, w 요소가 조작되지 않는다. (1로 되어있다.) 따라서 어떠한 효과도 없다.) orthographic projection은 perspective projection을 사용하지 않기 때문에, 더 멀리있는 객체들은 더 작게 보이지 않는다. 이것은 이상한 시각적 결과를 만들어 낸다. 이 이유 때문에, orthographic projection은 주로 2D 렌더링에 사용되고, 우리가 오히려 원근법에 의해 왜곡된 정점들을 가지지 않는 몇 몇 아키텍쳐 또는 엔지니어링 프로그램 을 위해서도 사용된다. 3D 모델링을 위해 사용되는 Blender 같은 프로그램은 모델링을 위해 orthographic projection을 사용한다. 왜냐하면 그것이 좀 더 정확히 각 오브젝트의 크기를 묘사하기 때문이다. 아래에서 너는 Blender에서 두 사영 방식의 비교를 볼 것이다.
너는 원근 사영으로, 더 멀리 있는 정점이 더 작다는 것을 볼 수 있다. 반면에 정사영에서 각 정점이 사용자에게 같은 거리를 갖는다.
Putting it all together
우리는 앞서 말한 단계들의 각각을 위한 변환 행렬을 만든다 : model, view 그리고 projection matrix. 정점 좌표는 그러고나서 clip 좌표로 다음과 같이 변환된다.
행렬 곱의 순서가 역이라는 것에 주의해라. (우리는 오른쪽에서 왼쪽으로 행렬 곱을 읽어야 한다는 것을 기억해라.) 최종 정점은 그 후에 vertex shader에서 gl_Position에 할당될 것이다. 그리고 OpenGL은 그 후에 자동적으로 perspective division과 clipping을 수행 할 것이다.
Green Box
And then?
vertex shader의 output은 좌표들이 우리가 변환 행렬들로 했었던 clip-space에 있기를 요구한다. OpenGL은 clip space 좌표들을 normalized-device 좌표들로 변환하기 위해 그 좌표들에 perspective division을 수행한다. OpenGL은 그 후에 NDC를 각 좌표가 너의 스크린에 있는 점에 대응되는 스크린 좌표로 매핑하기 위해 glViewPort의 파라미터들을 사용한다. (우리의 경우에 800x600 스크린). 이것은 viewport transform이라고 불려진다.
이것은 이해하기 어렵다. 그래서 만약 너가 각 공간이 무엇을 위해 사용되는지 아직 확실하지 않다면, 너는 걱정할 필요가 없다. 아래에서, 너는 우리가 어떻게 이 좌표들을 잘 사용하도록 할지 볼 것이고, 충분한 예시들이 이러한 튜토리얼에서 나올 것이다.
Going 3D
어떻게 3D 좌표들을 2D좌표로 변환하는지 알았으니, 우리는 우리의 오브젝트를 우리가 이제 껏 보여준 변변찮은 2D 면 대신에 실제 3D 객체로서 보여주기 시작할 수 있다.
3D로 그리는 것을 시작하기 위해서, 우리는 우선 model matrix를 만들 것이다. model matrix는 우리가 모든 객체의 정점을 변환하기 위해 그것을 global world spac에 적용하고자하는 이동, 스케일링 그리고/또는 회전으로 구성된다. 우리의 면을 조금 바꾸어보자. 그것을 x축에 대해 회전하자. 그래서 그것은 바닥에 누운 것처럼 보인다. 그 model matrix는 이렇게 보인다.
glm::mat4 model;
model = glm::rotate(model, glm::radians(-55.0f, glm::vec3(1.0f, 0.0f, 0.0f));
이 model matrix로 정점 좌표들을 곱하여, 우리는 정점 좌표들을 world 좌표들로 바꿀 것이다. 바닥에 있는 우리의 면은 따라서 global world에서 면을 상징한다.
다음에 우리는 view matrix를 만들 필요가 있다. 우리는 scene에서 뒤로 움직이길 원한다. 그래서 그 객체가 보일 수 있따. (world space에서 우리가 (0,0,0)에 위치해 있을 때.) 장면 주위에 움직이기 위해 다음의 것에 대해 생각해라 :
카메라를 뒤로 움직이려면, 전체 장면을 앞으로 움직이는 것과 같다.
이것은 정확히 view matrix가 하는 것이다. 우리는 카메라가 움직이는 것과 역으로 전체 장면을 움직인다. 우리가 뒤로 가기 원하기 때문에, 그리고 OpenGL은 오른손 좌표계이기 때문에 우리는 양의 z축으로 움직여야 한다. 우리는 이것을 장면을 음의 z축으로 이동시켜서 한다. 이것은 우리가 뒤로 움직이는 인상을 준다.
Green Box
Right-Handed System
전통적으로, OpenGL은 오른손 좌표계이다. 이것이 기본적으로 말하는 것은 양의 x축은 너의 오른쪽이고, 양의 y축은 위쪽, 양의 z축은 뒤쪽이다. 3개의 축의 중심인 너의 스크린을 생각해라. 양의 z축은 너의 스크린을 관통하여 너에게 향한다. 그 축들은 다음과 같이 그려진다.
왜 이것이 오른손 좌표계로 불려지는지 이해하려면 다음을 해라.
- 너의 오른쪽팔을 양의 y축을 따라 펼쳐라 너의 손을 위로 올리고
- 너의 엄지를 오른쪽을 향해라
- 너의 검지를 위로 향해라
- 이제 너의 중지를 90도 아래로 굽혀라
만약 너가 이것을 옳게 했다면, 너의 엄지는 양의 x축을 가리키고, 검지는 양의 y축을, 그리고 중지는 양의 z축을 가리킨다. 만약 너가 이것을 너의 왼팔로 한다면 너는 z축이 반대가 된 것을 볼 것이다. 이것은 왼손 좌표계로 알려져있고, 흔히 DirectX에서 사용된다. NDC에서 OpenGL은 실제로 왼손좌표계를 사용한다는 것에 주의해라. (사영 행렬이 그 handedness를 바꾼다.)
우리는 다음 튜토리얼에서 좀 더 세부적으로 장면들을 어떻게 움직일지를 이야기 할 것이다. 이제 view matrix는 이것처럼 보인다.
glm::mat4 view;
// note that we're translating the scene in the reverse direction of where we want to move
view = glm::translate(view, glm::vec3(0.0f, 0.0f, -3.0f));
우리가 정의할 필요가 있는 마지막은 사영 행렬이다. 우리는 우리의 scene을 위해 원근 사영을 사용하고 싶다. 그래서 우리는 그 사영 행렬을 이렇게 선언할 것이다.
glm::mat4 projection;
projection = glm::perspective(glm::radians(45.0f), screenWidth / screenHeight, 0.1f, 100.0f);
변환 행렬을 만들었으니 그것들을 쉐이더에 넘겨야 한다. 처음에 uniform 변수로 쉐이더에 변환행렬을 선언하고 그것들을 정점 좌표들에 곱해라.
#version 330 core
layout (location = 0) in vec3 aPos;
uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;
void main()
{
gl_Position = projection * view * model * vec4(aPos, 1.0);
}
우리는 또한 그 행렬들을 쉐이더로 보내야 한다. (이것은 보통 매 렌더 반복마다 된다. 변환행렬은 자주 바뀌는 경향이 있기 때문이다.
int modelLoc = glgetUniformLocation(ourShader.ID, "model");
glUniformMatrix4fv(modelLoc, 1, GL_FALSE, glm::value_ptr(model));
... // smae for View Matrix and Projection Matrix
우리의 정점 좌표들은 model, view, projection 행렬을 통해 변환되었으니, 최종 오브젝트는
- 바닥으로 뒤로 기울어져있고
- 우리로 부터 더 멀리 있고
- 원근감있게 보여진다. (정점들이 멀리 있을수록 더 작아져야 한다.)
결과가 실제로 이러한 요구사항을 하는지 봐보자.
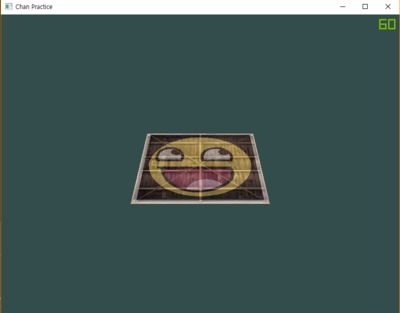
그것은 상상의 바닥에 있는 3D 면처럼 보인다. 만약 너가 같은 결과를 얻지 못했다면, 완전한 소스코드를 체크해라.
More 3D
지금까지 우리는 3D 공간에서 2D 면으로만 작업해왔다. 그래서 용기가 필요한 길을 가보자 그리고 우리의 2D 면을 3D 정육면체로 확장해보자. 정육면체를 렌더링하기 위해, 우리는 36개의 정점을 필요로 한다. (6개의 면 * 2 개의 삼각형 * 3 개의 정점). 36개의 정점들을 너무 많다. 그래서 너는 그것들을 여기에서 가져올 수 있다.
재미로, 우리는 큐브가 시간에 따라서 회전시킬 것이다.
model = glm::rotate(model, (float)glfwGetTime() * glm::radians(50.0f), glm::vec3(0.5f, 1.f, 0.f));
그리고나서 우리는 glDrawArrays를 사용하여 정육면체를 그리지만, 이번에는 36개의 정점들의 개수로 한다.
glDrawArrays(GL_TRIANGLES, 0, 36);
너는 다음과 비슷한 것을 얻을 것이다.

그것은 정육면체와 조금 비슷하지만, 무엇인가 이상하다. 정육면체의 몇 면들이 육면체의 다른 면들 위에 그려지고 있다. 이것은 OpenGL이 너의 정육면체를 삼각형마다 그릴 때, 비록 어떤 다른 것이 이전에 그려져있을지라도, 그것의 픽셀을 덮어쓸 것이기 때문에 발생한다. 이 때문에, 몇 삼각형들은 그것들이 겹쳐지지 않을동안, 서로 위에 겹쳐 그려진다.
운좋게도, OpenGL은 OpenGL이 한 픽셀위에 언제 그리고 안 그릴지를 결정하게 해주는 z-buffer라고 불려지는 한 버퍼에 depth 정보를 저장한다. 그 z-buffer를 사용하여, 우리는 OpenGL이 depth-testing을 하도록 설정할 수 있다.
Z-buffer
OpenGL은 depth buffer라고 알려진 z-buffer에 모든 그것의 depth 정보를 저장한다. GLFW는 자동적으로 너를 위해 그러한 버퍼를 생성한다. (output 이미지의 color들을저장하는 color-buffer를 가진 것처럼). 그 depth는 각 fragment내에 저장된다. (fragment의 z값 처럼) 그리고 fragment가 그것의 color를 만들어 내기 원할 때 마다, OpenGL은 그것의 depth value를z-buffer와 비교한다. 만약 현재 fragment가 다른 fragment 뒤에 있다면, 버려진다. 그렇지 않다면, 덮여씌워진다. 이 과정은 depth testing이라 불려지고 OpenGL에 의해 자동적으로 수행된다.
그러나, 만약 우리가 OpenGL이 실제로 depth testing을 수행하도록 하길 원한다면, 우리는 처음에 OpenGL에게 우리가 depth testing을 하고싶다고 말해야 한다. 그것은 기본적으로 disabled되어 있다. 우리는 glEnable을 사용하여 depth testing을 할 수 있게 한다. glEnable과 glDisable 함수는 우리가 OpenGL의 특정 기능들을 켜고 끌 수 있게 한다. 그 기능은 또 다른 호출이 그것을 disable/enable 할 때 까지 enabled/disabled 되어 있다. 지금 당장 우리는 GL_DEPTH_TEST를 활성화하여 depth testing을 할 수있게 하고 싶다.
glEnable(GL_DEPTH_TEST);
우리는 depth buffer를 사용하기 때문에, 우리는 또한 매 render iteration 전에 depth buffer를 클리어 하길 원한다. (만약 그렇게 안한다면, 이전 프레임의 depth 정보가 buffer에 남아 있는다.) color buffer를 clear하는 것처럼, 우리는 glClear 함수에서 DEPTH_BUFFER_BIT 비트를 명시하여 depth buffer를 클리어 할 수 있다.
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
우리의 프로그램을 다시 실행 시키고, OpenGL이 depth testing을 수행하는지 봐보자.

해냈다. 시간에 따라 회전하는 적절한 depth testing을 한 완전히 textured된 정육면체 이다. 여기에서 소스코드를 확인해라.
More cubes!
스크린에 10개의 정육면체를 그리고 싶다고 하자. 각 육면체는 같아 보일 것이지만, 그것이 각각 다른 회전을 가진 체 world에 위치해서 다를 것이다. 육면체의 그래픽적 layout은 이미 정의되어있다. 그래서 우리는 더 많은 오브젝트들을 렌더링할 때 우리의 버퍼 또는 attribute array들을 바꿀 필요가 없다. 우리가 각 오브젝트에 대해 바꿀 것은 우리가 육면체를 world속으로 변환할 때의 그것의 model matrix이다.
처음에, world space에서 그것의 위치를 명시하는 각 큐브의 이동 벡터를 정의하자. 우리는 glm::vec3 array에 10개의 육면체 위치를 정의할 것이다.
glm::vec3 cubePositions[] =
{
glm::vec3(0.0f, 0.0f, 0.0f),
glm::vec3(2.0f, 5.0f, -15.0f),
glm::vec3(-1.5f, -2.2f, -2.5f),
glm::vec3(-3.8f, -2.0f, -12.3f),
glm::vec3(2.4f, -0.4f, -3.5f),
glm::vec3(-1.7f, 3.0f, -7.5f),
glm::vec3(1.3f, -2.0f, -2.5f),
glm::vec3(1.5f, 2.0f, -2.5f),
glm::vec3(1.5f, 0.2f, -1.5f),
glm::vec3(-1.3f, 1.0f, -1.5f)
};
이제, 게임 루프 내에서, 우리는 glDrawArrays 함수를 10번 호출하고 싶어하지만, 이번에 렌더링하기전에 매번 vertex shaer에 다른 model matrix를 보낼 것이다. 우리는 game loop 안에 우리의 객체를 다른 model matrix로 10번 렌더링하는 작은 loop를 만들 것이다. 우리는 또한 각 컨테이너에 대해 작은 회전을 더한다는 것에도 주목해라.
for (unsigned int i = 0; i < 10; ++i)
{
glm::mat4 model(1.0f);
model = glm::translate(model, cubePositions[i]);
float angle = 20.0f * i;
model = glm::rotate(model, glm::radians(angle) * (float)glfwGetTime(), glm::vec3(1.0f, 0.3f, 0.5f));
ourShader.setMat4("model", model);
glDrawArrays(GL_TRIANGLES, 0, 36);
}
이 코드는 새로운 큐브가 그려질 때 마다 model matrix를 업데이트 시킬것이고, 이것을 총 10번 한다. 지금 당장 우리는 10개의 이상하게 회전된 큐브들로 채워진 world를 볼 것이다.

완벽하다. 마치 우리의 컨테이너가 맘에 드는 친구들을 찾은 것 같다. 만약 너가 막혔다면, 너의 코드를 소스코드와 비교해보아라.
Exercise
- GLM의 projection 함수의 FoV와 aspect-ratio로 가지고 실험해 보아라. 그러한 것들이 원근 frustum에 어떻게 영향을 미치는지를 알아낼 수 있는지 보아라.
perspective = glm::perspective(glm::radians(45.f), (float)SCR_WIDTH / SCR_HEIGHT, 10.f, 11.0f);
먼저 near, far plane 거리를 수정했다.
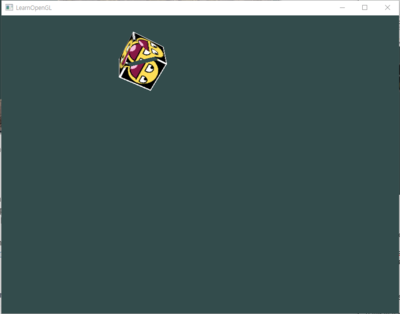
10개의 container가 안보이고 z축 기준으로 -10 ~ 0에 있는것들, ~ -11 에 있는 것들을 지워지고, 저기 하나만 남았다
glm::vec3(-1.7f, 3.0f, -7.5f), 아마 이 위치에 있는 cube같은데, cube의 크기 때문에 어떤 부분은 안보이고 보이기도 하는 것 같다.
1) FoV == 90
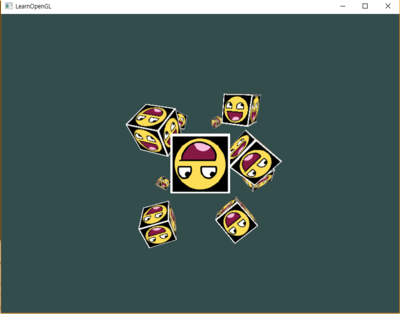
바라보는 원근 frustum의 각이 넓어지니 시야도 넓어졌다. 그에 따라, 오브젝트들도 크기가 작아졌다.
FoV를 90도에서 계속 늘리니, 화면에서 점점 멀어지고, 오브젝트들이 작아졌고. 180도에서 오브젝트들은 보이지 않았다.
아마, Fov가 180도면 뭔가 원근 frustum에서 맞지 않는 각도인가보다. 하지만, 180도를 넘어가면 작았던 오브젝트들이 점점 커진다.
2) FoV == 22

바라보는 원근 frustum의 각이 좁아지므로, 그 만큼 오브젝트들이 가까이 있어진다. near와 far plane의 거리는 이 FoV에 따라서 조절되는 것 같다.
1) aspect-ratio * 2
perspective = glm::perspective(glm::radians(45.0f), (float)SCR_WIDTH / SCR_HEIGHT * 2.f, 0.1f, 100.0f);
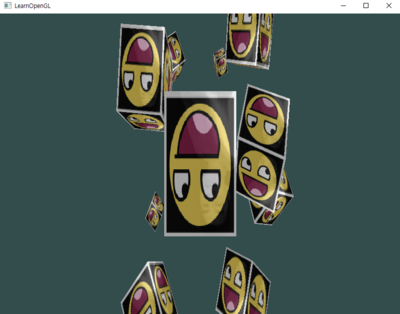
aspect_ratio를 두 배 했더니, 오브젝트가 뭔가 위 아래로 길어지고, 양옆으로는 줄어든 것 같다.
perspective = glm::perspective(glm::radians(45.0f), (float)SCR_WIDTH / SCR_HEIGHT / 2.f, 0.1f, 100.0f);

절반으로 나누었더니, 일단 전반적으로 더 크기 보이는데, 비율이 양옆으로 길어지고, 위아래로 줄어든 것 같다.
perspective = glm::perspective(glm::radians(45.0f), (float)SCR_WIDTH / SCR_HEIGHT + 5.f, 0.1f, 100.0f);

aspect_ratio에 5를 더했더니 확실히, 위아래로 길어지고, 양옆으로는 줄어들었다. 여기에 100 500을 했더니, 위아래로 엄청 길어지고, 양옆으로는 엄청 줄어들어서
위아래 색깔있는 직선만 보였다.
aspect_ratio에 뺄셈으로도 실험을 해보니, 비율이기 때문에 더하는 것과 비슷한 결과가 나왔다.
perspective projection의 원리에 대해 확실히 공부 해놓을 필요가 있다.
- 몇 가지 방향으로 이동하여 view matrix를 가지고 놀아라.그리고 장면이 어떻게 바뀌는지 보아라. view matrix를 camera object로 생각해라.
if (glfwGetKey(window, GLFW_KEY_W) == GLFW_PRESS)
view = glm::translate(view, glm::vec3(0.f, 0.f, 0.01f));
if (glfwGetKey(window, GLFW_KEY_S) == GLFW_PRESS)
view = glm::translate(view, glm::vec3(0.f, 0.f, -0.01f));
if (glfwGetKey(window, GLFW_KEY_A) == GLFW_PRESS)
view = glm::translate(view, glm::vec3(0.01f, 0.f, 0.f));
if (glfwGetKey(window, GLFW_KEY_D) == GLFW_PRESS)
view = glm::translate(view, glm::vec3(-0.01f, 0.f, 0.f));
if (glfwGetKey(window, GLFW_KEY_Q) == GLFW_PRESS)
view = glm::rotate(view, glm::radians(-0.1f), glm::vec3(0.f, 1.f, 0.f));
if (glfwGetKey(window, GLFW_KEY_E) == GLFW_PRESS)
view = glm::rotate(view, glm::radians(0.1f), glm::vec3(0.f, 1.f, 0.f));
간단한 카메라 기능을 구현했다. 따라서 WS로 Z축을 이동하고, AD로 X축을 이동한다. QE로 Y축에 대해 회전한다.
view matrix를 이해하는 가장 간단한 원리는, 카메라를 움직이는게 아니라 물체들을 움직이는 것이다.
현재 이것에는 문제가 있는데, 회전할 시에, translate가 남아있기에 중심점을 기준으로 회전하여, 제자리 회전이 안된다.
아마 다음 튜토리얼에서 이것을 해결할 수 있을 것이다.
- 시간에 따라 매 3번째 container들을 회전하도록 해라. (첫 번째 것도 포함하여), 반면에 다른 contaner들을 model matrix를 사용하여 정지한채 두어라.
for (unsigned int i = 0; i < 10; ++i)
{
glm::mat4 model(1.0f);
model = glm::translate(model, cubePositions[i]);
float angle = 20.0f * i;
if (i % 3 == 0)
angle *= glfwGetTime();
model = glm::rotate(model, glm::radians(angle), glm::vec3(1.0f, 0.3f, 0.5f));
ourShader.setMat4("model", model);
glDrawArrays(GL_TRIANGLES, 0, 36);
}
댓글 없음:
댓글 쓰기