Parallax Mapping
Parallax mapping은 normal mapping과 비슷한 기법이지만, 다른 원리에 기반을 한다. normal mapping과 유사하게, 그것은 매우 텍스쳐의 표면 디테일을 증가시키고 깊이감을 주는 기법이다. 그것 또한 환영이지만, parallax mapping은 깊이감을 전달하는데 있어서 훨씬 더 좋고 normal mapping과 함께 믿을 수 없이 현실적인 결과를 준다. parallax mapping이 (advanced) lighting과 관련하여 필수적인 기법이 아니지만, 나는 여전히 그것을 다룰 것이다. 왜냐하면 그 기법은 normal mapping에 논리적으로 따라나오는 것이기 때문이다. parallax mapping을 배우기 전에 normal mapping의 이해하는 것이, 특히 tangent space에 대해, 강하게 충고된다.
Parallax mapping은 텍스쳐 내부에 저장된 geometrical information을 기반으로 정점들을 displace or offset하는 (옮기는, 배치하는) displacement mapping techniques의 family에 속한다. 이것을 하는 한 가지 방법은 대략 1000개의 정점을 가진 평면을 가지고, 우리에게 특정한 구역에서의 평면의 높이를 말해주는 텍스쳐에 있는 값을 기반으로 이러한 정점들 각각을 배치시키는 것이다. texel마다 height values를 포함하는 그러한 텍스쳐는 height map이라고 불려진다. 간단한 brick surface의 geometric properties로부터 얻어지는 예제 height map은 이것처럼 보인다:
한 평면에 걸쳐질 때, 각 정점은 height map에 있는 샘플링된 height value를 기반으로 배치된다. 그리고 이것은 flat plane을 material의 geometric properties를 기반으로 대강 울퉁불퉁한 표면으로 바꾼다. 예를들어, flat plane을 위의 height map으로 배치시키면 다음의 이미지를 만들어낸다:
정점을 배치하는 것의 문제는 한 평면이 현실적인 배치를 얻기위해 많은 양의 삼각형들로 구성되어야 할 필요가 있다는 것이다. 그렇지 않으면 그 배치는 너무 blocky 해 보인다. 각 flat surface가 그러고나서 1000개 이상의 정점을 요구하기 때문에, 이것은 빠르게 연산적으로 그럴듯 하지 ㅇ낳다. 만약 우리가 어느정도 추가 정점 필요없이 유사한 realism을 얻을 수 있다면 어떨까? 사실, 만약 내가 너에게 위의 displaced surface가 실제로 오직 6개의 정점들 (또는 2개의 삼각형들)로만 렌더링되었다고 말한다면 어떨까? 이 보여지는 brick surface는 parallax mapping으로 렌더링된다. 그 mapping은 depth를 전달하는 추가 정점 데이터를 요구하지 않고 normal mapping과 유사하게 사용자를 속이기위해 똑똑한 기법을 사용하는 displacement mapping 기법이다.
parallax mapping뒤에 있는 아이디어는 fragment의 표면이 실제보다 더 높거나 또는 낮게 보이도록 텍스쳐 좌표를 변경하는 것이다. 이것 모두는 view direction과 heightmap을 기반으로 한다. 그것이 어떻게 작동하는지를 이해하기 위해, 우리의 brick surface의 다음의 이미지를 봐보자:
여기에 거친 빨간 선은 heightmap에서 brick surface의 geometric surface representation의 값을 나타내고, vector V는 표면에서 나가는 view direction을 나타낸다 (viewDir). 만약 그 평면이 실제 displacement를 가진다면, 그 viewer는 그 표면을 B지점에서 볼 것이다. 그러나 우리의 평면은 어떠한 displacement가 없기 때문에, 그 view direction은 우리가 기대하듯이 A점에 있는 flat plane에 닿는다. Parallax mapping은 fragment position A에 있는 텍스쳐좌표를 우리가 point B에서 텍스쳐 좌표를 얻도록 하는 방식으로 위치를 변경 시키는것을 목표로 한다. 우리는 그러고나서 point B에 있는 텍스쳐 좌표를 나중의 텍스쳐 샘플링을 위해 사용한다. 이것은 보는 사람이 실제로 point B를 바라보고 있는 것처럼 만든다.
trick은 어떻게 point A로부터 pointB에 있는 텍스쳐 좌표를 얻는가를 알아 내는 것이다. Parallax mapping은 fragment-to-view directioin vector V를 fragment의 높이로 스케일링하여 이것을 해결하려고 한다. 그래서 우리는 V의 길이를 fragment position A에서 heightmap H(A)로부터 샘플된 값과 동일 되게 스케일링 할 것이다. 아래의 이미지는 이 스케일된 vector P를 보여준다:
우리는 그러고나서 이 벡터 P를 취하고 텍스쳐 좌표 offset으로서 그 평면과 일치하는 그것의 벡터좌표를 취한다. 이것은 vector P가 heightmap의 height value를 사용하여 계산되기 때문에 작동한다. 그래서 한 fragment의 height가 더 높을수록 그것은 효과적으로 배치된다.
이 작은 트릭은 대부분 좋은 결과를 주지만, 하지만 정말 point B를 얻기위해 정말 조잡합 근사이다. 높이들이 표면에 대해 급하게 바뀔 때, 그 결과는 비현실적인 것처럼 보이는 경향이 있다. vector P가 너가 아래에서 보듯이 B에 가까이 가지 않을 것이기 때문이다:
parallax mapping의 또 다른 문제는 surface가 임의로 어떤 방식으로 회전될 때 P로부터 어떤 좌표를 얻어내는지 알아내기가 어렵다는 것이다. 우리가 오히려 하는 것은 다른 좌표 공간에서의 parallax mapping이다. 거기에서 vector P의 x와 y 컴포넌트는 항상 텍스쳐의 평면과 정렬한다. 만약 너가 normal mapping tutorial을 따라왔다면, 너는 아마도 우리가 이것을 어떻게 얻는지 추측한다. 그러다, 우리는 tangent space에서 parallax mapping을 하고 싶어 한다.
fragment-to-view direction vector V를 tangent space로 변형하여, 그 변형된 P vector는 표면의 tangent와 bitangent vectors에 정렬된 그것의 x와 y 컴포넌트를 갖을 것이다. tangent와 bitangent vectors들은 표면의 텍스쳐 좌표로서 같은 방향을 가리키고 있기 때문에, 우리는 P의 x와 y의 컴포넌트들을 표면의 방향과 상관없이 텍스쳐좌표 offset으로 취할 수 있다.
이론에 충분히 했으니, 우리의 발을 적셔보고 실제 parallax mapping을 구현해보자.
Parallax mapping
parallax mapping을 위해서, 우리는 GPU에 보내기전에 그것의 tangent와 bitangent vectors를 계산하여 간단한 2D 평면을 사용할 것이다; 우리가 normal mapping tutorial에서 한 것과 비슷하다. 우리는 diffuse texture, a normal map and a displacement map을 plane에 attach할 것이다. 너는 각각의 링크를 클릭하여 다운로드 할 수 있다. 이 예제에 대해, 우리는 normal mapping과 합하여 parallax mapping을 사용할 것이다. parallax mapping은 그것이 표면을 옮긴 환각을 주기 때문에, 조명이 어울리지 않을 때 깨진다. normal maps 종종 heightmaps로부터 생성되기 때문에, height map과 함꼐 normal map을 사용하는 것은 조명이 displacement와 함꼐 제자리에 있도록 한다.
너는 이미 위에 링크된 displacement map이 이 튜토리얼의 시작에서 보여준 heightmap과 거꾸로 된 것을 눈치챘을지도 모른다. parallax mapping과 함께, height map의 역으로 된 (depthmap으로도 알려진) 것을 사용하는 것이 좀 더 말이 된다. 왜냐하면 평평한 표면에서 height보다 depth를 가짜로 하는게 더 쉽기 때문이다. 이것은 다소 우리가 어떻게 parallax mapping을 인지할지를 바꾼다. 아래에서 보여지듯이:
우리는 또 다시 점 A와 B를 가지지만, 이번에 우리는 점 A의 텍스쳐좌표로부터 vector V를 빼서 vector P를 얻는다. 우리는 shaders에서 샘플링된 heightmap 값을 1.0에서 빼서 height values 대신에 depth values를 얻을 수 있다. 또는 간단히 그것의 텍스쳐 값을 이미지 편집 소프트웨어에서 역으로 하여 할 수도 있다. 우리가 위의 링크에서 depthmap으로 한 것 처럼.
Parallax mapping은 fragment shader에서 구현된다. displacement effect가 한 삼각형의 표면에 대해 모두 다르기 때문이다. fragment shader에서 우리는 fragemtn-to-view direction vector V를 계산할 필요가 있을 거싱다. 그래서 우리는 tangent space에 있는 view position과 fragment position을 필요로 한다. normal mapping tutorial에서 우리는 이미 이러한 tangent space에 있는 벡터들을 보내는 vertex shader를 가지고 있었다. 그래서 우리는 그 튜토리얼의 vertex shader의 정확한 복사본을 가져올 수 있다:
#version 330 core layout (location = 0) in vec3 aPos; layout (location = 1) in vec3 aNormal; layout (location = 2) in vec2 aTexCoords; layout (location = 3) in vec3 aTangent; layout (location = 4) in vec3 aBitangent; out VS_OUT { vec3 FragPos; vec2 TexCoords; vec3 TangentLightPos; vec3 TangentViewPos; vec3 TangentFragPos; } vs_out; uniform mat4 model; uniform mat4 view; uniform mat4 projection; uniform vec3 lightPos; uniform vec3 viewPos; void main() { gl_Position = projection * view * model * vec4(aPos, 1.0); vs_out.FragPos = vec3(model * vec4(aPos, 1.0)); vs_out.TexCoords = aTexCoords; vec3 T = normalize(vec3(model * vec4(aTangent, 0.0))); vec3 N = normalize(vec3(model * vec4(aNormal, 0.0))); T = normalize(T - dot(T, N) * N); vec3 B = cross(N, T); mat3 TBN = transpose(mat3(T, B, N)); vs_out.TangentLightPos = TBN * lightPos; vs_out.TangentViewPos = TBN * viewPos; vs_out.TangentFragPos = TBN * vs_out.FragPos; }
여기에서 주목해야할 중요한 것은 parallax mapping을 위해, 우리는 특히 aPos와 viwer의 position인 viewPos를 tangent space에서 fragment shader로 보내야 한다는 것이다.
fragment shader 내에서 우리는 parallax mapping logic을 구현한다. 그 fragment shader는 이것처럼 보인다:
#version 330 core out vec4 FragColor; in VS_OUT { vec3 FragPos; vec2 TexCoords; vec3 TangentLightPos; vec3 TangentViewPos; vec3 TangentFragPos; } fs_in; uniform sampler2D diffuseMap; uniform sampler2D normalMap; uniform sampler2D depthMap; uniform float height_scale; vec2 ParallaxMapping(vec2 texCoords, vec3 viewDir); // Blinn-Phong lighting system with normal/parallax mapping practice void main() { // offset texture coordinates with Parallax Mapping vec3 viewDir = normalize(fs_in.TangentViewPos - fs_in.TangentFragPos); vec2 texCoords = ParallaxMapping(fs_in.TexCoords, viewDir); // then sample textures with new texture coords vec3 diffuse = texture(diffuseMap, texCoords); vec3 normal = vec3(texture(normalMap, texCoords)); normal = normalize(normal * 2.0 - 1.0); // proceed with lighting code }
우리는 입력으로 fragment의 텍스쳐 좌표와 tangent space에 있는 fragment-to-view direction V를 받는 ParallaxMapping이라고 부릴는 함수를 정의했다. 그 함수는 옮겨진 텍스쳐 좌표를 반환한다. 우리는 그러고나서 이러한 옮겨진 텍스쳐 좌표를 diffuse와 normal map을 샘플링하기 위한 텍스쳐 좌표로 사용한다. 결과적으로 fragment의 diffuse color와 normal vector는 정확히 surface의 옮겨진 geometry에 부합한다.
ParallaxMapping 함수안을 봐보자:
vec2 ParallaxMapping(vec2 texCoords, vec3 viewDir) { float height = texture(depthMap, texCoords).r; vec2 p = viewDir.xy / viewDir.z * (height * height_scale); return texCoords - p; }
이 상대적으로 간단한 함수는 우리가 이제까지 이야기 한 것의 직접적인 번역이다. 우리는 원래의 텍스쳐 좌표 texCoords를 받고, depthMap으로부터 현재 fragment H(A)에서 height(or depth)를 샘플링하기위해 이것을 사용한다. 우리는 그러고나서 tangent-space에 있는 viewDir vector의 x와 y 컴포넌트를 그것의 z component로 나누고 그것을 fragment의 height로 스케일링해서 P를 구한다. 우리는 또한 몇 가지 추가 통제를 위해 height_scale uniform을 도입했다. parallax effect는 보통 추가 스케일 파라미터 없이는 너무 강하기 때문이다. 우리는 그러고나서 이 벡터 P를 최종 변경된 텍스쳐 좌표를 얻기위해 택스쳐 좌표로부터 뺀다.
여기에서 주목해야할 흥미로운 것은 viewDir.xy를 viewDir.z로 나누는 것이다. viewDir vector는 표준화되었기 때문에, viewDir.z는 0.0 ~ 1.0 사이의 범위에 있을 것이다. viewDir는 크게 그 표면에 평행할 때, 그것의 z component는 0.0에 가깝고, 그 나눗셈은 상당히 더 큰 벡터 P를 만든다. viewDir이 surface에 수직일 때에 비교해서. 그래서 기본적으로 우리는 표면을 top에서 바라볼 때와 비교한 각도로부터 그것이 텍스쳐 좌표를 더 큰 스케일로 위치시키도록 P의 크기를 증가시킨다; 이것은 각도에 따라 좀 더 현실적인 결과를 준다. 몇몇 사람들은 viewDir.z 나눗셈을 식에서 없애기를 선혼한다. 왜냐하면 normal Parallax Mapping이 바람직하지 않은 결과를 각도에 따라 만들어낼 수 있다; 그 기법은 그러고나서 Parallax Mapping with Offset Limiting이라고 불린다. 어떤 기법을 선택할지 고르는 것은 보통 개인 선호의 문제이지만, 나는 종종 normal Parallax Mapping의 편에 서는 경향이 있다.
그 최종 텍스쳐 좌표는 그러고나서 다른 텍스쳐들을 (diffuse and normal) 샘플링하기 위해 사용된다. 그리고 이것은 매우 깔끔한 displaced effect를 준다. 너가 height_scale이 대강 0.1인 것을 아래에서 볼 수 있듯이:

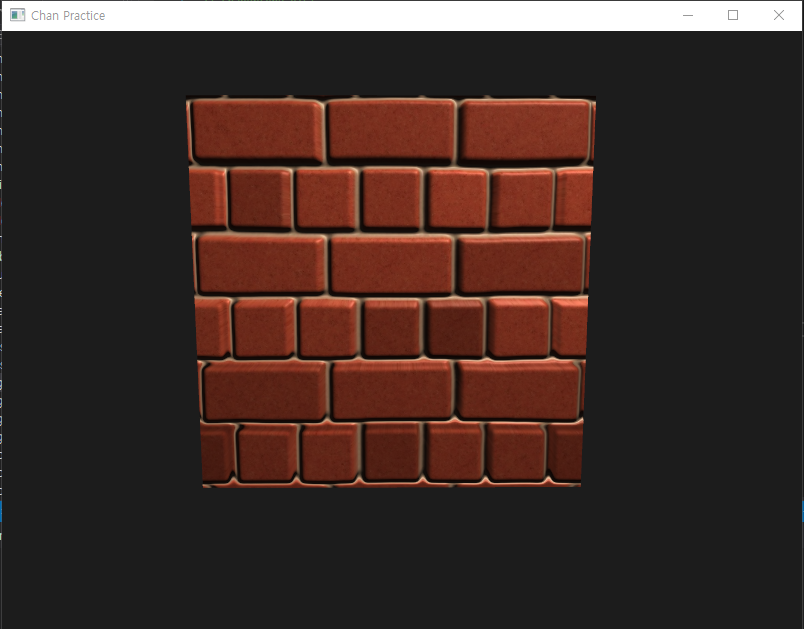
여기에서 너는 normal mapping과 normal mapping과 결합된 parallax mapping의 차이를 볼 수 있다. parallax mapping은 depth를 simulate하려고 하기 때문에, 실제로 벽돌이 너가 그것들을 보는 방향을 기반으로 다른 벽돌들을 덮으려고 하는 것이 가능하다.
너는 여전히 parallax mapped plane의 edge에서 몇몇 이상한 border artifacts를 볼 수 있다. 이것은 그 평면의 edges에서 displaced된 텍스쳐 좌표가 그 범위 [0,1]의 밖으로 oversample할 수있고, 이것이 텍스쳐의 wrapping mode에 기반으로 비현실적인 결과를 주기 때문에 발생한다. 이 문제를 해결하는 멋진 트릭은 그것이 기본 텍스쳐 좌표 범위를 벗어나서 샘플링할 때마다 그 fragment는 버리는 것이다:
vec2 texCoords = ParallaxMapping(fs_in.TexCoords, viewDir); if (texCoords.x > 1.0 || texCoords.y > 1.0 || texCoords.x < 0.0 || texCoords.y < 0.0) discard;
기본 범위 밖의 (displaced) 텍스쳐 좌표들이 있는 모든 fragments들은 버려지고, Parallax Mapping은 그러고나서 surface의 edges 주변에 적절한 결과를 준다. 이 트릭은 모든 종류의 표면에 적절히 작동하지 않는다는 것에 주목해라. 그러나 한 평면에 적용될 때, 그것은 그 평면이 실제로 이동된 것처럼 보이게 만든다:

너는 여기에서 소스코드를 볼 수 있다.
그것은 훌륭해 보이고 꽤 바르다. 뿌남ㄴ 아니라, 우리는 오직 parallax mapping을 작동시키기 위해 오직 하나의 추가 텍스쳐 샘플만 필요하다. 그것은 그것을 한 각도에서 바라 볼 때 그것이 어느정도 무너져 내리고 가파른 높은 변화와 부정확한 결과를 주는 몇 가지 문제가 있다. 아래에서 너가 볼 수 있듯이:
그것이 때때로 적절히 작동하지 않는 이유는 그것이 displacement mapping의 조잡한 근사이기 때문이다. 그러나 여전히 우리가 거의 가파른 height changes를 가진 곳에서 완벽한 결과를 얻게 하는 몇 가지 추가 트릭들이 있다. 심지어 한 각도에서 바라볼 때. 예를들어, 만약 우리가 한 sample 대신에 B의 가장 가까운 점 B를 찾기 위해 여러가지 샘플들을 취하면 어떨까?
Steep Parallax Mapping
Steep Parallax Mapping은 Parallax Mapping에 더해지는 확장이다. 그것이 같은 원칙을 사용하지만 1개의 샘플 대신에 더 좋은 B에 대한 vector P를 정하기 위해 여러 샘플들을 취한다는 점에서. 이것은 훨씬 더 좋은 결과를 준다. 심지어 가파른 높이 변화에서도. 그 기법의 정확성은 샘플들의 개수대로 개선된다.
Steep Parallax Mapping의 일반적인 아이디어는 총 depth range를 같은 height/depth의 수많은 레이어들로 나누는 것이다. 이러한 레이어들 각각에 대해, 우리는 현재 layer의 depth value보다 낮은 sampled depth value를 찾을 때 까지 P의 방향을 따라 텍스쳐 좌표를 옮기면서 depthmap을 샘플링한다. 다음의 이미지를 봐보자:
우리는 위아래로 depth layers를 가로지르고, 각 layer에 대해, 우리는 그것의 깊이 값을 depth map에 저장된 depth value와 비교한다. 만약 그 레이어의 depth value가 depthmap의 value보다 작다면, 그것은 이 vector P의 레이어 부분이 그 표면 아래에 있지 않다는 것을 의미한다. 우리는 그 layer의 depth가 depth map에 저장된 값보다 더 클 때 까지 이 과정을 계속한다: 이 점이 그러고나서 (displaced된) geometric surface아래에 있다.
이 예제에서, 우리는 두 번째 layer (D(2) = 0.73)은 여전히 두 번째 layer의 값 0.4보다 더 낮다는 것을 볼 수 있다. 그래서 우리는 계속한다. 다음 반복에서, 그 layer의 depth value 0.6은 depthmap의 샘플된 depth value (D(3) = 0.37)보다 더 높다. 우리는 따라서 세 번째 layer에 있는 벡터 P가 displaced geometry의 가장 가능한 위치라고 가정할 수 있다. 우리는 그러고나서 vector P_3로부터 fragment의 텍스쳐 좌표를 displace하기 ㅜ이해 텍스쳐 좌표 offset T_3를 취한다. 너는 그 정확도가 좀 더 depth layers와 함께 어떻게 증가하는지를 볼 수 있다.
이 기법을 구현하기 위해서, 우리는 오직 ParallaxMapping 함수를 바꿔야만 한다.우리가 이미 필요한 변수들을 가지고 있기 때문이다:
vec2 ParallaxMapping(vec2 texCoords, vec3 viewDir) { // number of depth layers const float numLayers = 10; // calculate the size of each layer float layerDepth = 1.0 / numLayers; // depth of current layer float currentLayerDepth = 0.0; // the amount to shift the texture coordinates per layer (From vector P) vec2 P = viewDir.xy * height_scale; vec2 deltaTexCoords = P / numLayers; }
여기에서 우리는 처음에 설정을한다: layer의 개수를 명시하고, 각 layer의 depth를 계산한다 그리고 마침내 layer마다 P의 방향을 따라 shift해야만 하는 텍스쳐 좌표 offset을 계산한다.
우리는 그러고나서 모든 layers들에 대해 반복한다. 이것은 가장 위에서부터 시작하고. layer의 depth value보다 더 작은 depthmap value를 찾을 때 까지 한다:
vec2 ParallaxMapping(vec2 texCoords, vec3 viewDir) { // number of depth layers const float numLayers = 10; // calculate the size of each layer float layerDepth = 1.0 / numLayers; // depth of current layer float currentLayerDepth = 0.0; // the amount to shift the texture coordinates per layer (From vector P) vec2 P = viewDir.xy * height_scale; vec2 deltaTexCoords = P / numLayers; // get initial value vec2 currentTexCoords = texCoords; float currentDepthMapValue = texture(depthMap, currentTexCoords).r; while(currentLayerDepth < currentDepthMapValue) { // shift texture coordintates allong direction of P; currentTexCoords -= deltaTexCoords; // get depthmap value at current texture coordinates currentDepthMapValue = texture(depthMap, currentTexCoords).r; // get depth of next layer currentLayerDepth += layerDepth; } return currentTexCoords; }
여기에서 우리는 각 depth layer에 대해 반복하고, (displaced된) surface의 아래에 있는 depth를 처음에 반환하는 vector P를 따라있는 texture coordinate offset을 찾을 떄까지 하고 멈춘다. 최종 offset은 최종 displaced coordinate vector를 얻기 위해 fragment의 텍스쳐 좌표로부터 빼진다. 이번에는 전통적인 parallax mapping과 비교해서 좀 더 정확성을 가지게 된다.
약 10개의 샘플들로 그 brick surface는 좀 더 그럴듯 해 보인다. 심지어 우리가 그것을 어떤 각도에서 볼 때에도. 그러나 steep parallax mapping은 이전에 보여진 전시된 나무 장난감 표면 같은 steep height changes가 있는 복잡한 표면을 가질 때 정말 효과가 좋다.
우리는 Parallax Mapping의 특성 중 하나를 이용하여 그 알고리즘을 조금 개선시킬 수 있다. 한 표면을 직접바라 볼 떄, 많은 텍스쳐 displacement가 없다. 반면에 한 표면을 한 각도에서 바라볼 때 많은 displacement가 있다. (두 경우에 view direction을 시각화 시켜라). 표면을 직접바라 볼 때는 샘플을 덜 취하고, 한 각도에서 볼 떄는 더 많은 샘플을 취하여 우리는 오직 필요한 양의 샘플을 취하게 된다:
const float minLayers = 8.0; const float maxLayers = 32.0; float numLayers = mix(maxLayers, minLayers, abs(dot(vec3(0.0, 0.0, 1.0), viewDir)));
여기에서 우리는 viewDir과 양의 z 방향의 내적을 취하고, 우리가 표면을 바라보는 각도에 기반하여 minLayers or maxLayers에 좀더 샘플들의 개수를 맞추기 위해서 그것의 결과를 사용한다. (양의 z 방향이 tangent space에서 표면의 normal vector와 같다는 것에 주목해라). 만약 우리가 표면과 평행한 방향으로 본다면, 우리는 32개의 layers를 사용할 것이다.
너는 여기에서 업데이트된 소스코드를 볼 수 있다. 너는 또한 여기에서 wooden toy box surface를 여기에서 찾을 수 있다.
Steep Parallax Mapping은 또한 문제가 있다. 그 기법은 유한 개수의 샘플들을 기반으로 하기 때문에, 우리는 aliasing effects를 갖게되고 레이어들 사이의 명백한 구분은 쉽게 포착될 수 있다:
우리는 많은 수의 샘플들을 취하여 그 문제를 줄일 수 있찌만, 이것은 성능에 너무 큰 짐이 된다. (displaced) surface의 아래에 있는 첫 위치를 취하지 않고 B에 더욱 가까운 match를 찾기위해 그 위치의 두 개의 가장 가까운 depth layers들 사이를 보간하여 그 문제를 해결하는 목표가 몇 가지 있다.
이러한 접근법들 중 인기있는 두 가지는 Relief Parallax Mapping과 Parallax Occlusion Mapping이라고 불려지는데, Relief Parallax Mapping은 가장 정확한 결과를 주지만, Parallax Occlusion Mapping에 비교해서 너무 성능이 무겁다. Parallax Occlusion Mapping은 거의 Relief Parallax Mapping과 같은 결과를 주고 또한 효율적이기 때문에, 그것이 종종 선호되는 접근법이고 또한 우리가 다룰 마지막 Parallax Mapping의 종류이다.
Parallax Occlusion Mapping
Parallax Occlusion Mapping은 Steep Parallax Mapping과 같은 원칙에 기반을 두지만, 충돌 후의 첫 번째 depth layer의 텍스쳐 좌표를 취하는 대신에, 우리는 충돌 전후의 depth layer 사이를 선형으로 보간할 것이다. 우리는 그 surface의 높이가 depth layer의 두 레이어 값으로부터 얼마나 멀리있는지에 선형 보간의 가중치를 둔다. 그것이 어떻게 작동하는지 이해하기 위해 다음의 사진을 봐보자:
너도 볼 수 있듯이, 추가 단계로서 교차점을 둘러싸는 두 depth layer의 텍스쳐 좌표 사이를 선형보간이 있는 Steep Parallax Mapping과 크게 비슷하다. 이것은 또 다시 근사이지만, 상당히 Steep Parallax Mapping보다 더 정확하다.
Parallax Occlusion Mapping의 코드는 Steep Parallax Mapping의 확장이고 너무 어렵지 않다:
vec2 ParallaxOcclusionMapping(vec2 texCoords, vec3 viewDir) { // number of depth layers const float minLayers = 8.0; const float maxLayers = 32.0; float numLayers = mix(maxLayers, minLayers, abs(dot(vec3(0.0, 0.0, 1.0), viewDir))); // calculate the size of each layer float layerDepth = 1.0 / numLayers; // depth of current layer float currentLayerDepth = 0.0; // the amount to shift the texture coordinates per layer (From vector P) vec2 P = viewDir.xy * height_scale; vec2 deltaTexCoords = P / numLayers; // get initial value vec2 currentTexCoords = texCoords; float currentDepthMapValue = texture(depthMap, currentTexCoords).r; while(currentLayerDepth < currentDepthMapValue) { // shift texture coordintates allong direction of P; currentTexCoords -= deltaTexCoords; // get depthmap value at current texture coordinates currentDepthMapValue = texture(depthMap, currentTexCoords).r; // get depth of next layer currentLayerDepth += layerDepth; } // get texture coordinates before collision (reverse operations) vec2 prevTexCoords = currentTexCoords + deltaTexCoords; // get depth after and before collision for linear interpolation float afterDepth = currentDepthMapValue - currentLayerDepth; float beforeDepth = texture(depthMap, prevTexCoords).r - currentLayerDepth + layerDepth; // interpolation of texture coordinates float weight = afterDepth / (afterDepth - beforeDepth); vec2 finalTexCoords = prevTexCoords * weight + currentTexCoords * (1.0 - weight); return finalTexCoords; }
(displaced) surface geometry를 교차시킨 후의 depth layer를 찾은 후에, 우리는 또한 교차 이전의 depth layer의 texture coordinates를 얻는다. 다음으로 우리는 대응되는 depth layers로부터 (displaced) geometry의 depth의 거리를 계산하고 이러한 두 값들 사이를 보간한다. 그 선형 보간은 두 레이어의 텍스쳐 좌표사이의 기본 보간이다. 그 함수는 그러고나서 마침내 최종 보간된 텍스쳐 좌표를 반환한다.
Parallax Occlusion Mapping은 놀랍게도 좋은 결과를 주고, 비록 몇 가지 작은 artifacts와 aliassing issues가 여전히 보이지만, 일반적으로 좋은 trade-off이다. 그리고 매우 심하게 줌인 될 때 또는 매우 가파른 각도에서 볼떄 그러한 artifacts들이 보인다.

너는 소스 코드를 여기에서 볼 수 있다.
Parallax Mapping은 너의 scene의 세부사항을 증가시키는 훌륭한 기법이지만, 그것을 사용할 때 너가 고려해야할 몇가지 artifacts들이 있다. 대부분 종종 parallax mapping은 바닥이나 벽 같은 표면들에 사용된다. 거기에서 그 surface의 outline을 결정하는 것은 쉽지않고, 바라보는 각도는 대부분 종종 표면에 수직이다. 이 방식으로 Parallax Mapping의 artifacts는 눈치챌만하지 않다. 그리고 너의 오브젝트의 세부사항을 증진시키기 위한 놀랍게도 흥미로운 기법으로 만든다.
Additional resources
- Parallax Occlusion Mapping in GLSL : snandblackcat.com의 훌륭한 parallax mapping tutorial. 여기에는 self shadowing에 대한 것 까지 있다. 근데 POM만 적용해도 shadowing이 어느정도 되는것 같은데. 좀 더 세부적으로 보고싶다면 여기 마지막부분을 참고하면 좋을듯 하다.
- How Parallax Displacement Mapping Works : The Benny Box가 만든 parallax mapping이 어떻게 작동하는지에 대한 좋은 비디오 튜토리얼.
====================================
이론을 이해하느라 너무 힘들고 오래걸렸다. 이것은 상당히 scene의 details을 올려주기 때문에 normal mapping과 함꼐 반드시 적용해야할 것이다. normal mapping은 기본적으로 다 적용하고, normal mapping + Parallax Occlusion Mapping은 floor와 wall같은 곳에 중점적으로 적용해서 scene의 details을 살리자.
댓글 없음:
댓글 쓰기